免費咨詢熱線
0731-84988138
免費咨詢熱線
0731-84988138
來源于:河北友元管道制造有限公司
發布時間:2026-04-26 12:06:38
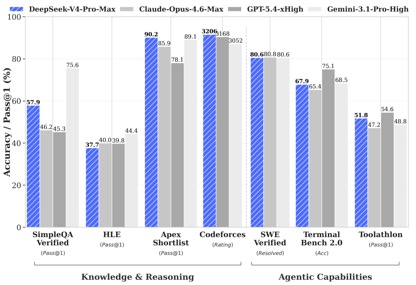
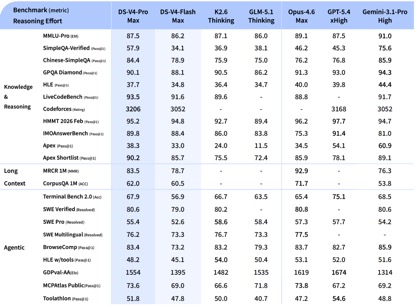
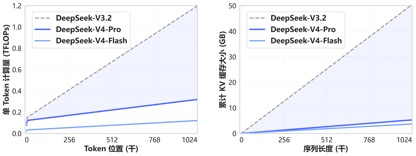
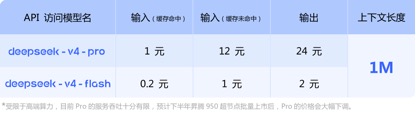
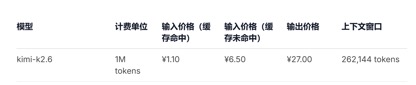
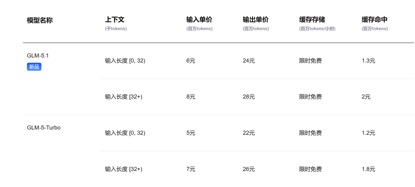
文 丨《BUG》欄目 周文猛 DeepSeek-V4預覽版本,價格屠夫終于發布了。把百萬 今日,上下適配昇騰DeepSeek官方宣布:擁有百萬字超長上下文的文打deepseek-v4-pro和deepseek-v4-flash兩款模型發布并開源,即日起登錄官網或官方App即可與最新的到毛DeepSeek-V4對話,探索1M(百萬)超長上下文記憶的國產格全新體驗,API服務已同步更新。腰斬 據官方公布基準測評,價格屠夫在上下文長度、把百萬知識、上下適配昇騰推理及Agent等能力上,文打DeepSeek V4性能比肩國際頂級閉源模型,到毛達到國際開源模型一流水平。國產格《BUG》欄目對比發現,腰斬在API調用價格上,價格屠夫去年以一己之力撬動國內大模型行業降價的DeepSeek,V4版本再次開出了行業“最低價”。 “雖然每百萬Tokens調用價格國內模型均未下降太多,但超長上下文長度及不俗的性能,讓其極具競爭優勢!”有業內人士在與《BUG》欄目溝通中感慨:“那個大模型價格屠夫,又回來了!” 性能比肩頂級閉源模型,知識、推理能力領先 根據DeepSeek的官方介紹,V4系列共包括兩個版本模型:DeepSeek-V4-Pro總參數1.6T、激活參數49B,預訓練數據33T;DeepSeek-V4-Flash總參數284B、激活參數13B,預訓練數據32T;兩者均原生支持100萬token上下文。 據DeepSeek披露的基準測試數據,在知識與推理類測試中,DeepSeek-V4-Pro-Max在Apex Shortlist和Codeforces兩項測試中取得了最優性能,超越Claude-Opus-4.6-Max、GPT-5.4-xHigh、Gemin-3.1-Pro-Hight等國際模型,展現了極強的邏輯與算法能力;在SimpleQA Verified測試中較Gemini-3.1-Pro-High略有差距但領先于Claude和GPT。 在Agentic能力測評中,V4、Opus-4.6、Gemin-3.1-pro三款模型在SWE Verified任務上打成平手,且DeepSeek在Toolathlon任務上取得了僅次于GPT-5.4-xHigh的水平,在Terminal Bench 2.0上取得了優于Opus-4.6的水平,體現了在復雜指令執行與工具調用場景下的優勢。 目前DeepSeek-V4已成為公司內部員工使用的Agentic Coding模型,根據評測反饋使用體驗優于Sonnet 4.5,交付質量接近Opus 4.6 非思考模式。 在數學、STEM、競賽型代碼的測評中,DeepSeek-V4-Pro 超越當前已公開評測的絕大多數開源模型,取得了比肩世界頂級閉源模型的成績。 綜合來看,在知識處理及推理能力上,DeepSeek-v4取得了較國內開源模型全方位領先,比肩國際的測評能力。但在Agentic能力方面,雖然最新的DeepSeek-v4有了不錯的提升,但較國內及國際第一梯隊的能力并未拉開差距,彼此各有領先。 “標配”100萬上下文,價格屠夫“回來了” 相比于各項基準測試中體現的性能優勢,本次V4發布最大的特色,莫過于長文本能力的突破以及API調用價格的進一步下探。 得益于DeepSeek-V4開創的全新注意力機制,V4通過在token維度進行壓縮并結合DSA稀疏注意力(DeepSeek Sparse Attention),實現了全球領先的長上下文能力,且相比傳統方法大幅降低了對計算和顯存的需求,將1M(一百萬)上下文變成了DeepSeek所有官方服務的標配。 一年前,100萬上下文還是Gemini的獨家王牌,即使是近期發布的多數主流國產開源模型中,模型上下文的長度也多位于128K—200K區間,而DeepSeek直接把百萬上下文從“高端閉源功能”,做成了開源標配。 在API價格調用上,相較于目前GLM-5.1輸入單價1.3元-2元/百萬Tokens(緩存命中),以及Kimi-K2.6 1.1元/百萬tokens(緩存命中),DeepSeek-v4 -pro及flash兩個版本,輸入單價分別為1元/百萬tokens及0.2元/百萬tokens,雖然價格降幅不大但均為最低,且上下文長度擴展了數倍。 (DeepSeek-v4系列模型API調用價格) (Kimi-k2.6模型API調用價格) (GLM-5.1模型API調用價格) “DeepSeek-v4此次發布帶來的性能突破,較DeepSeek-R1發布時帶給外界的沖擊要小了一些,各項性能依然處于第一梯隊,但領先優勢并未完全拉開。”在業內人士看來,“此次V4模型的發布,更多的在于長文本能力的提升及價格的進一步下探。” 該人士感慨道:“此前DeepSeek-V3及R1模型發布后,其通過底層技術創新帶來的性能優勢,直接推動整個國內大模型行業集體降價,雖然此次V4版本每百萬Tokens調用價格較國內同行并未下降太多,但依然具有競爭力,那個大模型價格屠夫又回來了!”。 “下半年批量上華為算力,Pro價格會大幅下調” 值得注意的是,在DeepSeek-v4公布API價格的信息的最下層位置,官方特別標注指出:“受限于高端算力,目前Pro的服務吞吐量十分有限,預計下半年昇騰950超節點批量上市后,Pro的價格會大幅下調。” 這意味著,此次發布的v4系列模型,已經針對華為昇騰950超節點完成適配,只要昇騰950上市,廣大用戶便可基于國產算力用上比肩國際頂級閉源模型的DeepSeek-v4。 在官方開源的技術文檔中,DeepSeek也提及了這一點,直言v4已在NVIDIA GPU和HUAWEI Ascend NPUs平臺上驗證了精細粒度的EP(專家并行)方案,相較于強大的非融合基線,其在通用推理任務上可實現1.50-1.73倍的加速效果,而在對時延敏感的場景(如RL推演和高速代理服務)中則可達到1.96倍的加速效果。 而在V4發布后,華為昇騰也同步宣布“超節點全系列產品支持DeepSeek V4系列模型”。據悉,昇騰950通過融合kernel和多流并行技術降低Attention計算和訪存開銷,大幅提升推理性能,結合多種量化算法,實現了高吞吐、低時延的DeepSeek V4模型推理部署。 本月上旬,英偉達創始人黃仁勛在接受Dwarkesh Patel專訪時曾言:“如果DeepSeek先在華為平臺上發布,那對我們國家(美國)來說將是災難性的。”在黃仁勛看來,雖然DeepSeek是一款開源模型,同樣可被用于英偉達產品上,但如果DeepSeek專門針對華為算力進行優化,在高端算力采購受限等局限下,英偉達將處于劣勢。 如今看來,雖然DeepSeek也針對英偉達算力進行了EP方案驗證,但黃仁勛擔心的事情還是發生了。在業內人士看來,“V4是算力博弈逼出來的產物,在未來一年,國產大模型跑在國產卡上,將逐漸成熟。” 多模態能力仍未出現 比較遺憾的是,DeepSeek V4雖然發布了,但該版本依然是一款純文本模型,沒有太多的文生圖、文生視頻等多模態能力。這也讓普通用戶快速體驗評測一款模型,平添了不少難度。 畢竟,在大語言模型能力不斷提升、幻覺率逐漸下降的當下,常規、單一的知識問答,已很難客觀反映一款模型的綜合能力。對于多數用戶而言,想要直觀感受V4模型的能力,還得下載并親自用上一陣子。 V4系列模型發布的同時,近期DeepSeek還曝出了計劃融資500億元的消息,有接近DeepSeek的知情人士透露,DeepSeek融前估值為3000億元,約合440億美元,目前騰訊控股、阿里巴巴集團均正在洽談投資DeepSeek。不過,對于融資相關事宜,DeepSeek方面至今未正面回應媒體問詢。 或許,對于DeepSeek創始人梁文鋒而言,在全球大模型“智力”增長放緩,行業人才競爭加劇、行業多模態化、Agentic化趨勢不斷凸顯的情況下,借V4發布適時融資壯大實力,也不失為一個明智之舉。 責任編輯:張喬松 




 海量資訊、精準解讀,盡在新浪財經APP
海量資訊、精準解讀,盡在新浪財經APP
 返回首頁
返回首頁

